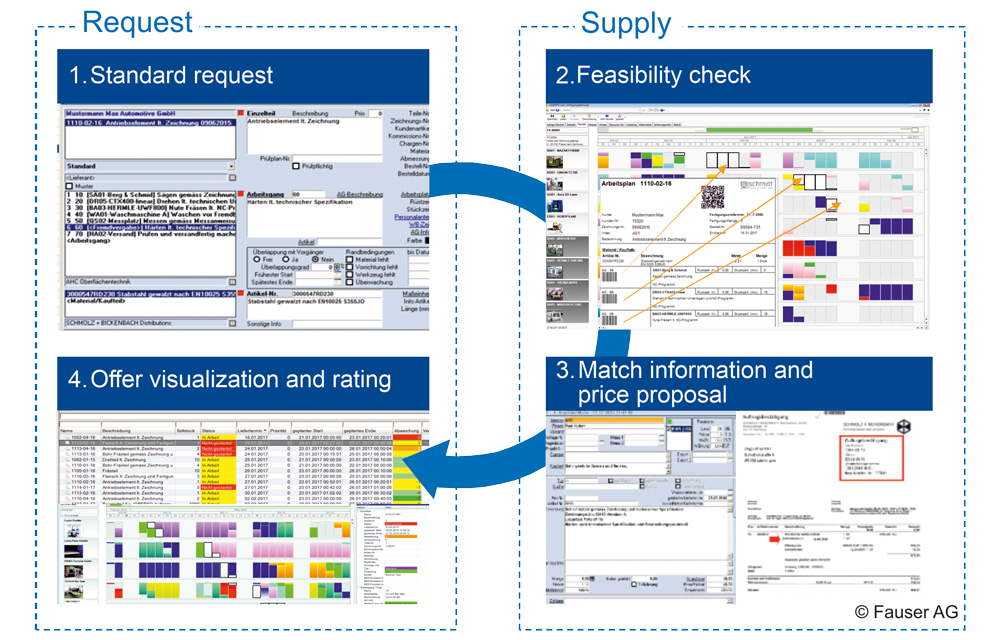
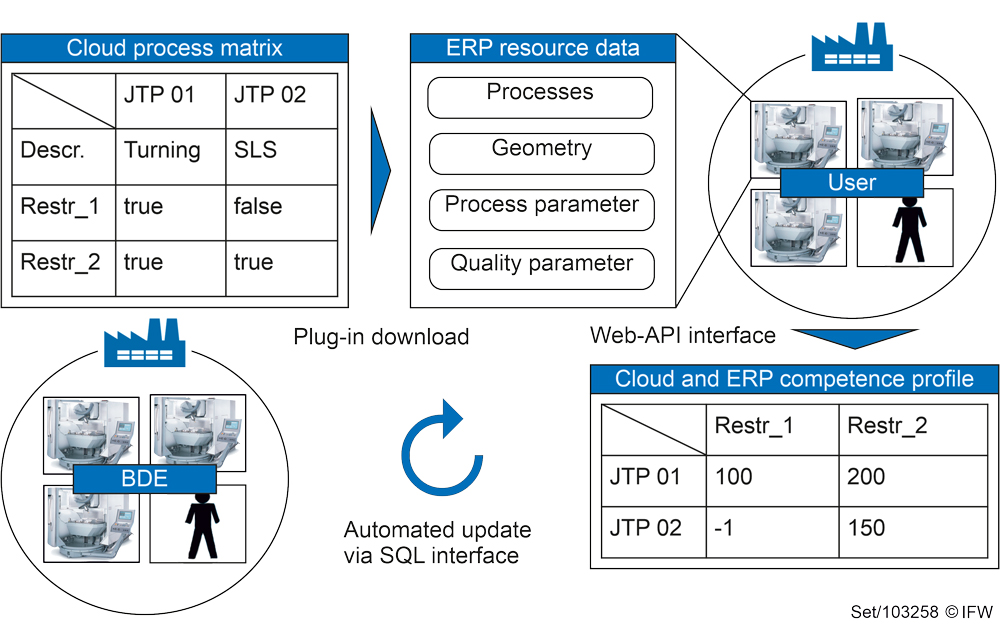
In the JobTRADE project, scientists at the Institute of Production Engineering and Machine Tools (IFW) are developing an assistance system for the trading of manufacturing capacities, especially of contract manufacturers (see Figure 2).
The aim is to significantly reduce sales time – by selecting technologically suitable customer requests and estimating machining and set-up times for standard workpieces, for example in turning and milling. Tools from the field of machine learning serve as the basis for the predictions. The solution is developed and integrated with Enterprise Resource Planning (ERP) and Manufacturing Execution Systems (MES) from FAUSER AG.
Data acquisition in practice
In addition to selecting the appropriate algorithm, the decisive factor for the successful use of machine learning methods is training with meaningful data. The fact that the acquisition of relevant order data to support decisions is of great value is already known to many companies that invest in the recording of operational data.
For detailed predictions, artificial intelligence requires a data base with several thousand entries. Thus, training data must first be collected over an extended period of time. Here, it must be taken into account that inaccurate order feedback, summarization of set-up and processing times or unconsidered machine malfunctions can make it difficult for the machine learning to recognize causal relationships. Contract manufacturers should therefore already take the requirements of future digitization projects into account when designing the level of detail of data acquisition.
In order to be able to make predictions despite grown data structures, methods for data preprocessing are used within the framework of JobTRADE.
Possibilities of data preprocessing
The challenge of data preprocessing lies in the cross-company and cross-process character of the trading platform. The methods to be used must therefore be suitable for automated operation with a wide range of varying input data. In order to process a data set accordingly, standardized modules in the Python programming language are available, which are adapted and combined to the data structure of the use case.
In the specific case of processing time forecasting, all relevant information is first summarized in a data sheet. This includes item identification data – i.e., name and item number – for the period of several years, the reported processing time, and other attributes that may be related to the effort – for example, dimensions and process specifics.
The next step is to remove rows of items that contain missing values. The next step is to automatically identify outliers with feedback times that are not effort-based. Without removing these non-representative articles, the apparent correlations of order attributes of these articles to effort can become disproportionately influential – especially when the amount of data is small. Identifying such an item purely on the basis of absolutely high or low confirmation times is not trivially possible due to the large differences between products. An automated cluster analysis helps to clarify this.
Set-up and processing time prediction
The article data can now be used without disturbing zero values and outliers in order to carry out prognoses by machine learning or statistical evaluations promising success. Neural networks for turning and milling processes are currently being trained for use on the JobTRADE platform. For this purpose, article information with an influence on the machining time is automatically identified by a correlation analysis. The parameters of the neural network are also optimized so that it can be used across processes. However, ERP and MES do not usually record detailed manufacturing processes separately by technology, which makes forecasting difficult. Initial analyses for turned parts show that the machining time estimate for the combined ERP group "CNC turning" and the planning data of the sales department achieve comparable accuracy (see Figure 3). Since the feedback and part data of the example processes can be recorded in much more detail, the scientists see great potential in future digitized factories.
In order to enable contract manufacturers to get started at short notice with low data density, the IFW is developing another algorithm. This recognizes similar articles and set-up operations in the database. Attributes of the articles that are related to the machining or set-up time are compared and a similarity measure is determined. In this way, similar articles can be displayed to the sales department with just a few clicks and statistically validated processing times can be suggested. In the context of sequence planning, the method identifies practical set-up times by evaluating similar set-up processes that have been carried out. Taking the delivery date into account, the most favorable resource allocation is to be selected.
The forecast can relieve the sales department and be used for the automated creation of offer prices. In the next step, cost models and the corresponding web application will be developed for this purpose. Companies interested in testing the machining and set-up time forecast should contact project manager Simon Settnik at +49 (0)511 762-18352 or via e-mail to settnik@ifw.uni-hannover.de.
Funding reference
The project "Assistance System for Automated Trading of Production Capacities" is supported by funds from the European Regional Development Fund (ERDF) and the State of Lower Saxony under the code ZW 3- 85035663.