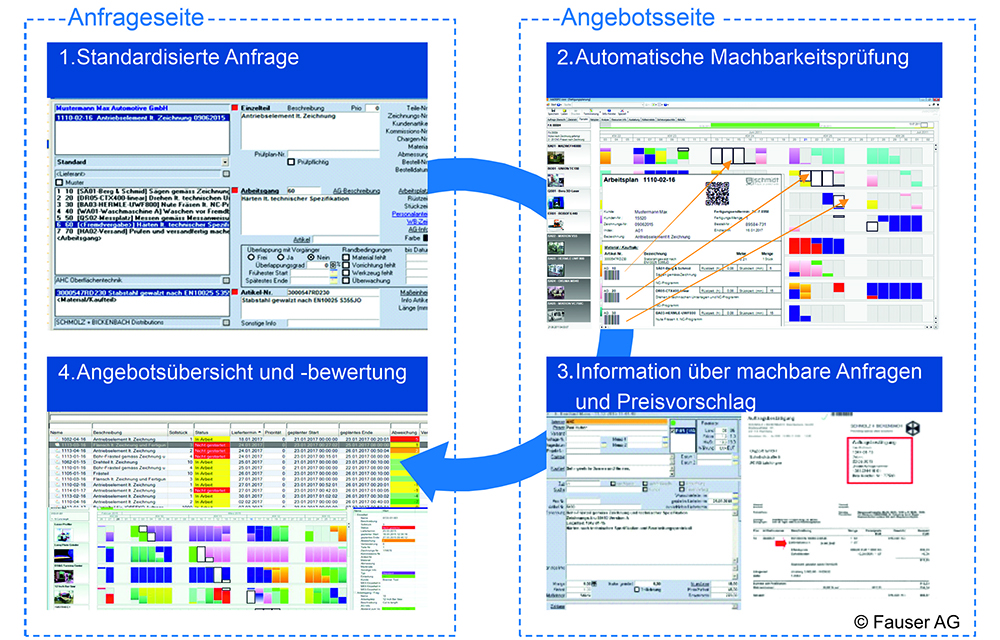
Im Projekt JobTRADE entwickeln Wissenschaftler des Instituts für Fertigungstechnik und Werkzeugmaschinen (IFW) ein Assistenzsystem für den Handel mit Fertigungskapazitäten insbesondere von Lohnfertigern (siehe Bild 2).
Ziel ist es, die Vertriebszeit deutlich zu reduzieren – durch die Auswahl technologisch passender Kundenanfragen und Schätzung der Bearbeitungs- und Rüstzeiten für Standardwerkstücke zum Beispiel in der Dreh- und Fräsbearbeitung. Werkzeuge aus dem Bereich des maschinellen Lernens dienen als Grundlage für die Vorhersagen. Entwickelt und integriert wird die Lösung mit Enterprise Resource Planning (ERP) und Manufacturing Execution Systemen (MES) der FAUSER AG.
Datenerfassung in der Praxis
Ausschlaggebend für den erfolgreichen Einsatz von maschinellen Lernmethoden ist neben der Auswahl des passenden Algorithmus das Anlernen mit aussagekräftigen Trainingsdaten. Dass die Erfassung relevanter Auftragsdaten zur Unterstützung von Entscheidungen von großem Wert ist, ist bereits vielen Unternehmen bekannt, die in die Aufnahme von Betriebsdaten investieren.
Für detaillierte Vorhersagen benötigt künstliche Intelligenz eine Datengrundlage mit mehreren Tausend Einträgen. Somit müssen zunächst über einen längeren Zeitraum Trainingsdaten erfasst werden. Hierbei ist zu berücksichtigen, dass eine ungenaue Auftragsrückmeldung, Zusammenfassung von Rüst- und Bearbeitungszeiten oder unberücksichtigte Maschinenstörungen das maschinelle Erkennen von kausalen Zusammenhängen erschweren kann. Bereits bei der Auslegung des Detaillierungsgrades der Datenerfassung sollten Lohnfertiger daher die Anforderungen zukünftiger Digitalisierungsprojekte berücksichtigen.
Um Vorhersagen trotz gewachsener Datenstrukturen treffen zu können, werden im Rahmen von JobTRADE Methoden zur Datenvorverarbeitung eingesetzt.
Möglichkeiten der Datenvorverarbeitung
Die Herausforderung der Datenaufbereitung liegt im unternehmens- und prozessübergreifenden Charakter der Handelsplattform. Die einzusetzenden Methoden müssen somit geeignet für den automatisierten Betrieb mit einer großen Bandbreite variierender Inputdaten sein. Um einen Datensatz entsprechend zu bearbeiten bieten sich standardisierte Module in der Programmiersprache Python an, die an die Datenstruktur des Anwendungsfalls angepasst und kombiniert werden.
Im konkreten Fall der Bearbeitungszeitprognose werden zunächst alle relevanten Informationen in einem Datenblatt zusammengefasst. Dazu gehören die Artikelidentifikationsdaten – also Name und Artikelnummer – für den Zeitraum mehrerer Jahre, die rückgemeldete Bearbeitungszeit sowie weitere Attribute, die in Verbindung mit dem Aufwand stehen können – beispielsweise Abmessungen und Prozessspezifika.
Im nächsten Schritt werden Zeilen mit Artikeln entfernt, die fehlende Werte enthalten. Anschließend gilt es, Ausreißer mit nicht aufwandsbegründeten Rückmeldezeiten automatisiert zu erkennen. Ohne Beseitigung dieser nicht repräsentativen Artikel können die scheinbaren Zusammenhänge von Auftragsattributen dieser Artikel zum Aufwand überproportional einfließen – besonders bei geringer Datenmenge. Einen solchen Artikel rein aufgrund absolut hoher oder niedriger Rückmeldezeiten zu identifizieren, ist aufgrund der großen Unterschiede der Produkte untereinander nicht trivial möglich. Zur Aufklärung trägt eine automatisierte Clusteranalyse bei.
Rüst- und Bearbeitungszeitprognose
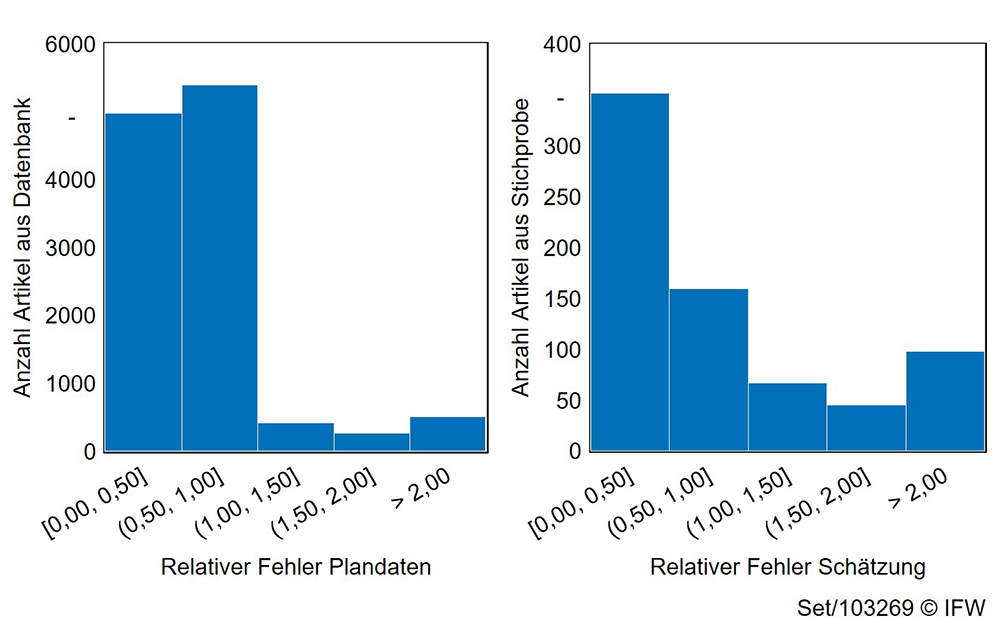
Die Artikeldaten können nun ohne störende Nullwerte und Ausreißer genutzt werden, um Prognosen durch maschinelles Lernen oder statistische Auswertungen erfolgsversprechend auszuführen. Für den Einsatz auf der JobTRADE Plattform werden aktuell neuronale Netze für Dreh- und Fräsprozesse angelernt. Hierzu werden Artikelinformationen mit Einfluss auf die Bearbeitungszeit automatisch durch eine Korrelationsanalyse identifiziert. Die Parameter des neuronalen Netzes werden ebenfalls optimiert, sodass es prozessübergreifend einsetzbar ist. Allerdings werden im ERP und MES Fertigungsverfahren in der Regel nicht detailliert technologisch getrennt erfasst, was die Prognose erschwert. Erste Analysen für Drehteile zeigen jedoch, dass die Bearbeitungszeitschätzung für die zusammengefasste ERP-Gruppe „CNC-Drehen“ und die Plandaten des Vertriebs eine vergleichbare Genauigkeit erreichen (siehe Bild 3). Da die Rückmelde- und Artikeldaten der Beispielprozesse noch deutlich detaillierter erfasst werden können, sehen die Wissenschaftler großes Potenzial in zukünftig digitalisierten Fabriken.
Um bei geringer Datendichte Lohnfertigern einen kurzfristigen Einstieg zu ermöglichen, entwickelt das IFW einen weiteren Algorithmus. Dieser erkennt ähnliche Artikel und Rüstoperationen in der Datenbank. Attribute der Artikel, die mit der Bearbeitungs- beziehungsweise Rüstzeit in Zusammenhang stehen, werden verglichen und ein Ähnlichkeitsmaß bestimmt. Dem Vertrieb können so mit wenigen Klicks ähnliche Artikel angezeigt und statistisch abgesicherte Bearbeitungszeiten vorgeschlagen werden. Im Rahmen der Reihenfolgeplanung identifiziert die Methode praxistaugliche Rüstzeiten durch Auswertung ähnlicher durchgeführter Rüstprozesse. Unter Berücksichtigung des Liefertermins soll die günstigste Ressourcenzuordnung ausgewählt werden.
Die Prognose kann den Vertrieb entlasten und zur automatisierten Erstellung von Angebotspreisen eingesetzt werden. Im nächsten Schritt werden hierzu Kostenmodelle und die entsprechende Webanwendung entwickelt. Unternehmen, die an einem Test der Bearbeitungs- und Rüstprognose interessiert, melden sich bei Projektleiter Simon Settnik unter der Telefonnummer (0511) 762-18352 oder per E-Mail an settnik@ifw.uni-hannover.de.