Die Verarbeitung von Kautschuk wird durch zahlreiche Einflussgrößen bestimmt. Durch die hohe Anzahl an Steuergrößen, chargenabhängigen Materialschwankungen insbesondere des Naturkautschuks und der bestehenden Systemträgheit gestaltet sich die manuell durchgeführte Prozesssteuerung fehleranfällig. In der Praxis basieren Steuervorgänge vorwiegend auf Anwendererfahrungen und erfolgen weder automatisiert noch digitalisiert. Daher wird am Institut für Transport- und Automatisierungstechnik (ITA) in Zusammenarbeit mit dem Forschungsverbund DIGIT RUBBER an der Digitalisierung des Kautschukextrusionsprozesses durch die Implementierung von Data-Mining- und KI-Systemen gearbeitet.
Data-Mining zur Identifikation von Zusammenhängen
Für die Entwicklung einer KI-basierten Steuerung müssen zunächst prozessbedingte Wirkzusammenhänge identifiziert werden, um Korrelationen zwischen den Steuer- und Messgrößen zu ermitteln. Auf Basis dieser Zusammenhänge können vorgegebene Toleranzgrenzen für die jeweiligen Messgrößen eingehalten werden. Ein ausgezeichneter Ansatz zur Identifikation von Wirkzusammenhängen ist das sogenannte Data-Mining.
Beim Data-Mining handelt es sich um einen Teilbereich der KI, in dem durch statistische Modelle und künstliche neuronale Netze (KNN) aus großen Datenmengen Muster und Trends erkannt werden. Der Anwendungsbereich erstreckt sich über Klassifikations- und Clusteranalysen bis hin zur Regressionsanalyse. Ein wesentlicher Vorteil gegenüber anderen Korrelationsanalysen, wie beispielsweise dem Pearson-Koeffizienten für lineare Modelle, ist, dass durch KNN auch nicht linearere Zusammenhänge ermittelt werden. Insbesondere für den komplexen Kautschukextrusionsprozess, der sich aus den Teilprozessen Mischen, Walzen und Extrudieren (siehe Bild 1) zusammensetzt, ist diese Analysetiefe von hoher Relevanz, um eine möglichst große Menge an Zusammenhängen in der Modellierung berücksichtigen zu können. Eine weitere Herausforderung besteht in der hohen Systemträgheit, die bei einer Reihe von Steuergrößen auftritt, wie zum Beispiel der Bereichstemperierung. Bestimmte Solltemperaturen können dadurch teilweise erst nach mehreren Minuten erreicht werden. Daher ist es erforderlich, prozessimmanente Wirkzusammenhänge möglichst genau zu prognostizieren, um auf Toleranzabweichungen entsprechend frühzeitig reagieren zu können.
Lernprozess von Data-Mining und KI-Systemen
Im Rahmen der Prozessmodellierung werden die aufgenommenen Messdaten zunächst entsprechend ihrer Eigenschaften zusammengefasst und klassifiziert. Da die Genauigkeit des Modells stark von der Güte der zur Verfügung stehenden Daten abhängt, müssen fehlerhafte und für den Anwendungsfall irrelevante Daten gefiltert, Redundanzen entfernt und Skalierungsmethoden angewendet werden. Für die weiterführende Unterstützung des maschinellen Lernprozesses folgt anschließend die Hyperparameteroptimierung des Algorithmus. Durch eine iterative Vorgehensweise werden dabei die Steuerungsparameter des Lernprozesses angepasst, um für die Prognose des Kautschukextrusionsprozesses bestmögliche Ergebnisse zu erzielen. In Abhängigkeit der Komplexität des zu hervorsagenden Wertes müssen beispielsweise die Topologie des Neuronalen Netzes erweitert oder die Anzahl an Iterationsschritten für die Gewichtung (Batches) angepasst werden.
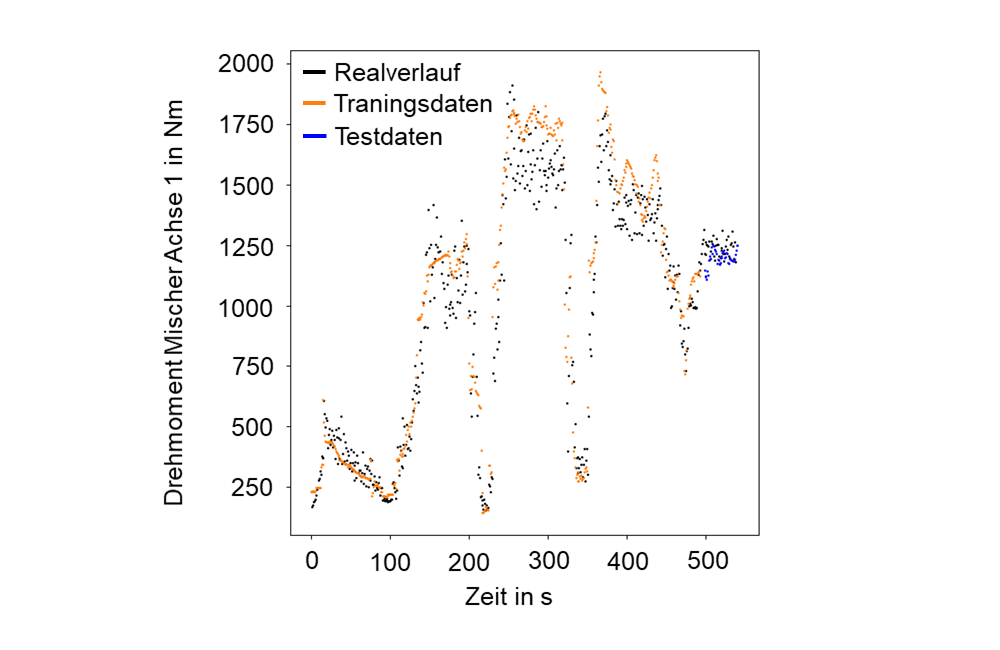
In erster Instanz erfolgt die Validierung der Data-Mining und KI-Modelle, indem nur ein Teil der Versuchsdaten (80 %) zum Trainieren eingesetzt werden, wohingegen die verbleibenden Versuchsdaten (20 %) als Referenz für die Prognose dienen. Für Teilprozesse der Kautschukextrusionsanlage konnte das ITA in diesem Zusammenhang bereits erste Erfolge erzielen (siehe Bild 2). Aus der Abbildung kann der Messverlauf des Drehmoments in Abhängigkeit der Zeit für den Mischprozess (siehe Bild 3) der Kautschukextrusionskette entnommen werden. Die ausschließlich aus den Steuergrößen berechneten Trainings- (orange) und Testverläufe (blau) des Data-Mining-Modells zeigen bereits eine gute Approximation des Realverlaufs (schwarz). Damit besteht die Möglichkeit, steuerungsrelevante Messgrößen hervorzusagen. Die Prognosegenauigkeit des Data-Mining Modells soll in den folgenden Schritten durch zusätzliche Trainingsdaten und weiterführende Modelloptimierungen gesteigert und auf weitere Prozesse übertragen werden.
KI-basierte Steuerung zur Minimierung von Prozessabweichungen
Zielsetzung der KI-basierten Steuerung ist es, dass auf Basis der im Data-Mining identifizierten Wirkzusammenhänge vorgegebene Toleranzgrenzen eingehalten werden. Wie das Data-Mining Modell basiert auch die KI-induzierte Steuerung der Kautschukextrusionsanlage auf künstlichen neuronalen Netzen. Hierbei werden jedoch Messgrößen als Eingangsdaten für das KI-Modell eingesetzt, um eine Vorgabe der Steuergrößen in Abhängigkeit der vorgegebenen Toleranzgrenzen zu berechnen und bei Abweichungen entsprechend gegenzusteuern. Die berechneten Vorgabesteuergrößen sollen abschließend durch das Data-Mining Modell validiert und bei hinreichender Genauigkeit an die Hardwareschnittstelle weitergeleitet werden.
Die Entwicklung und Implementierung der KI-induzierten Steuerung in die bestehende Kautschukextrusionsanlage ist für das Jahr 2023 geplant. In Zusammenarbeit mit dem Forschungsverbund DIGIT RUBBER wird eine Hardwareschnittstelle in das System integriert, mit der die KI-induzierten Steuerung unter realen Produktionsbedingungen validiert werden kann. Durch die erfolgreiche Implementierung kann die Ausschussquote von Kautschukextrusionsanlagen reduziert und die Prozessstabilität nachhaltig erhöht werden.