Die Planung von Lieferterminen in der Instandsetzung von Flugzeugtriebwerken wird durch diverse Faktoren beeinflusst. Dazu zählt beispielsweise die Informationsunschärfe hinsichtlich des Schadensbildes eines Flugtriebwerkes. Die jeweiligen Beschädigungen sind von unterschiedlichen Bedingungen abhängig. So können sich etwa je nach Einsatzort des Triebwerks unterschiedliche Beschädigungen der Triebwerksbauteile ergeben. Hängt ein Triebwerk an einem Flugzeug, welches vorwiegend über Wüstenregionen fliegt, kann dies ein anderes Schadensbild generieren als bei einem Triebwerk, welches an einem Flugzeug befestigt ist, das in der Regel über der nördliche Hemisphäre unterwegs ist.
Künstliche Intelligenz soll Terminplanung verbessern
Zu Beginn des Instandhaltungsprozesses liegt zwar bereits ein ungefähres Schadensbild vor. Jedoch steht erst nach der Befundung das genaue Schadensbild und damit der exakte Instandhaltungsaufwand fest. Zudem können auch während des Reparaturprozesses Störeinflüsse die Terminplanung erschweren. Beispielsweise können kurzfristig auftretende Kapazitätsengpässe die Planung der Reparaturaufträge beeinflussen. Dies wirkt sich daraufhin meist auch auf alle nachgelagerten Bereiche aus, sodass eine aktualisierte Auftragssteuerung über die verschiedenen Bereiche erforderlich ist.
Für die Produktionsplanung und -steuerung ergibt sich hieraus die Herausforderung, trotz dieser Einflussfaktoren eine hohe Planungsgüte zu gewährleisten. Daher forschen das IFA und die MTU Maintenance Hannover GmbH gemeinsam nach einer Möglichkeit, mithilfe von Künstlicher Intelligenz (KI) bereits frühzeitig valide Liefertermine in der Terminplanung berücksichtigen zu können. Darüber hinaus spielt auch die Erkennbarkeit der Treiber längerer Lieferzeiten eine wesentliche Rolle, um die Ergebnisse der KI praxisorientiert nutzen zu können.
Erstellung von Lieferzeitprognosen
Lieferzeitprognosen basieren in der Praxis zumeist auf Erfahrungen und Expertenwissen. Datengestützte KI-Methoden, wie etwa Modelle des Maschinellen Lernens (ML), bieten das Potential unbekannte Muster und Trends in Vergangenheitsdaten zu erkennen. Durch das in den Daten implizit vorhandene und so verwertbare Wissen können herkömmliche Lieferzeitprognosen verbessert werden. Dies ermöglicht es Unternehmen, Liefer- und Durchlaufzeiten präziser anzugeben und die Liefertermintreue zu steigern.
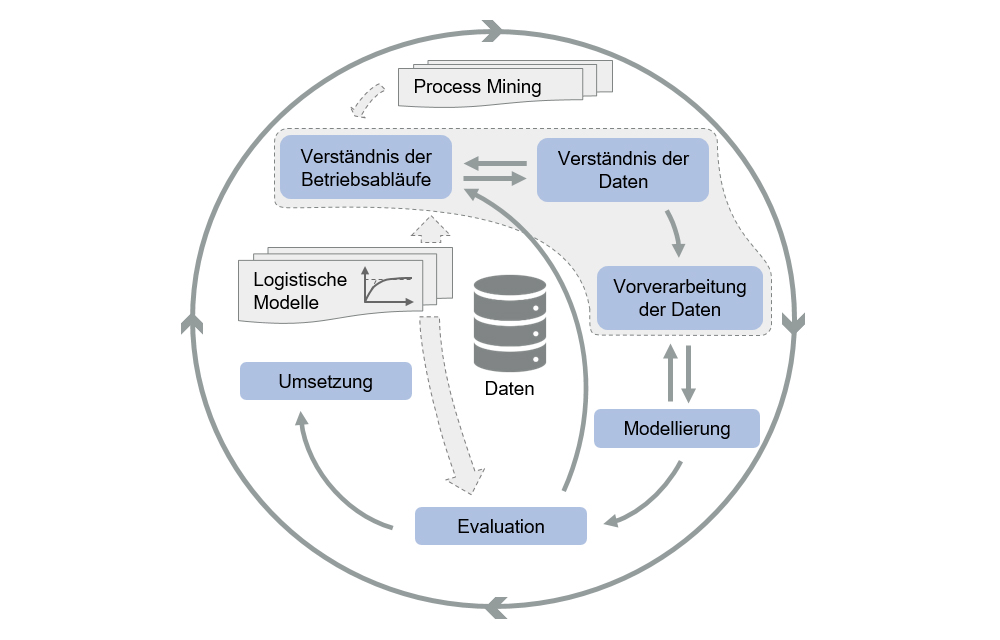
Die meiste Zeit in der Entwicklung eines ML-Modells beansprucht oftmals die Analyse der Produktions- und Logistikprozesse in Unternehmen, die Identifizierung relevanter Daten, der Aufbau des Datenverständnisses und die Datenvorverarbeitung (siehe CRISP-DM Prozess, Bild 2). Die erfolgreiche Identifizierung und Verarbeitung der zugrundeliegenden Daten bestimmen jedoch maßgeblich die Prognosegüte. Eingangsdaten von Prognosemodellen des (überwachten) maschinellen Lernen bestehen aus unabhängigen Variablen (Features) und einer abhängigen Variable. Ziel ist es, aussagekräftige Features zu erzeugen, um eine präzise Prognose zu ermöglichen. Dazu müssen mögliche Einflüsse auf die Durchlaufzeit und weitere Daten identifiziert sowie bedarfsgerecht beschrieben werden.
Die Einflüsse auf Liefer- und Durchlaufzeiten sind komplex und Treiber oftmals nur schwierig zu erkennen. Abweichungen von Plan-Losen, zu hohe Auftragsbestände, Reihenfolgevertauschen, Störungen beim Transport oder fehlerhafte Kapazitätsangaben können Durchlaufzeitabweichungen (vom Plan) begünstigen. Das Verständnis über die logistischen Wirkzusammenhänge in der Produktion ist daher maßgeblich, um Treiber von Durchlaufzeitabweichungen zu erkennen und aussagekräftige Features zu erzeugen.
Logistische Prozessanalysen wie etwa Korrelationsanalysen zur Identifikation der Art der Reihenfolgebildung können dabei helfen, das Systemverständnis zu verbessern und relevante Einflüsse auf die Durchlaufzeit zu erkennen und zu beschreiben. Ferner können Beschreibungs- und Wirkmodelle genutzt werden, um aussagekräftige Features zu erzeugen. Durch das mit (allgemeingültigen) logistischen Modellen explizit und formalisierte ausgedrückte (logistische) Prozesswissen ist es möglich, das implizite Wissen von Entscheidungsträgern in Unternehmen sinnvoll zu ergänzen und den Prozess der Datenidentifizierung und -vorverarbeitung zu unterstützen. Darüber hinaus können logistischen Modelle dabei helfen, die Prognoseergebnisse zu validieren und in den Ablauf der Produktionsplanung und -steuerung zu integrieren.
Besseres Verständnis – bessere Prognosemodelle
KI-Methoden können nur das verarbeiten, was ihnen übergeben wurde: „Garbage In – Garbage Out“. Werden unpassende Datenquellen und somit irrelevante Features zur Erstellung von Prognosemodellen genutzt, sind ungenaue Ergebnisse wahrscheinlich. Durch die Analyse mittels logistischer Modelle und der damit verbundenen Kenntnis über die Treiber von Durchlaufzeitabweichungen wird das Systemverständnis und die Transparenz der Produktionsprozesse erhöht sowie letztlich die Erzeugung aussagekräftiger Features unterstützt.
Unternehmen können durch ein modellgestütztes Vorgehen befähigt werden, eigenständig Prognosemodelle zu erstellen. Begünstigt wird dies durch zahlreiche innovative Entwicklungen im Bereich des Maschinellen Lernens (Low Code, AutoML), welche den eigentlichen Einsatz von ML auch ohne Programmierkenntnisse ermöglichen.